
Jako správce sítě budete možná muset vyřešit problémy se špatným výkonem aplikací.
Pro mnoho aplikací je nyní k dispozici adekvátní šířka pásma sítě, dokonce i globálně, takže zpoždění a ztráta paketů v síti LAN jsou pravděpodobnější než nedostatek šířky pásma.
Síťové komponenty (zařízení) slouží na trase mezi pobočkami a datovými centry, mimo jiné, pro zkvalitnění poskytování služeb. Tyto síťové komponenty aktivně pracují se síťovým provozem za účelem zlepšení propustnosti a snížení latence.
V ideálním světě by řešení Application Performance Management (APM) nebo Application-aware Network Performance Management (AANPM) mělo automaticky izolovat chyby a poskytovat všechny diagnostické informace, které jsou potřebné pro nápravná opatření. Realita je ale mnohem složitější. Interaktivní problémy, neočekávané chování aplikací nebo sítí, špatná konfigurace nebo touha po spolehlivých důkazech o chybách vyžadují ruční analýzu problémů správcem sítě.
V tomto článku vysvětlíme možná omezení výkonu, jak je změřit a kvantifikovat, ukážeme jejich dopad a navrhneme smysluplná vysvětlení a možné způsoby jejich nápravy. Jde o identifikaci potenciálních problémů s výkonem, jejich rychlejší, přesnější řešení a efektivnější práci s uživateli a vlastníky aplikací.
V tomto článku se diagramy toků paketů používají k ilustraci toků zpráv v síti. Pro tento účel byly definovány následující konvence diagramu:
Každá šipka představuje paket TCP
Šedé šipky se používají k zobrazení datových paketů
Červené šipky se používají k reprezentaci paketů TCP-ACK
Časová osa vždy běží odshora dolů.

Obrázek 1: Vývojový diagram paketů
Předpokládáme, že komunikace klient-server prostřednictvím mechanismu request/reply je založena na transportním protokolu TCP/IP. Tento postup se používá téměř ve všech interaktivních aplikacích. Patří mezi ně webové aplikace, aplikace fat klientů, přístupy k souborovému serveru, přenosy souborů, zálohy atd. Vzhledem k tomu, že se bere v úvahu pouze protokol TCP/IP, jsou vyloučeny hlasové a video aplikace. Ty využívají jiné přenosové protokoly.
Pro každou operaci existuje alespoň jeden požadavek a jedna odpověď na aplikační vrstvě. Tyto jednotky se nazývají datové jednotky protokolu aplikační vrstvy (PDU). Jednoduchá interakce klient-server vypadá takto: Na aplikační vrstvě je do klientského TCP stacku (TCP socket) předán požadavek na segmentaci (do paketů), adresování a přenos. Funkce poskytované zásobníkem TCP jsou obvykle zcela transparentní pro aplikační vrstvu.
Na přijímacím konci spojení (serveru) jsou data aplikace extrahována z paketů přenášených přes síť a znovu sestavena jako zprávy aplikační vrstvy a doručena přidružené službě ke zpracování.
Jakmile je dokončeno interní zpracování aplikační vrstvy, server předá odpověď zásobníku TCP serveru. Text zprávy je segmentován a přenášen klientovi přes síť. Výkon této výměny informací s request/reply je určen dvěma faktory:
Rychlost zpracování zpráv na serveru nebo klientovi
Doba, po kterou jsou zprávy přenášeny po síti.
Obě oblasti by proto měly být v analýze výkonnosti posuzovány samostatně. Informace znovu sestavené po přenosu představují síťově orientovaný pohled na aplikaci, zatímco pakety shromážděné Allegro Multimetrem v nahraném souboru pcap nás informují o tom, jak efektivně síť zprávy přenáší.
Většina informací na aplikační vrstvě je přenášena ve více datových paketech. Velikost informačního segmentu je typicky větší než maximální velikost segmentu MSS nebo velikost užitečného zatížení, které může být přenášeno síťovým paketem. To je typicky 1460 bajtů pro Ethernet. Pakety přiřazené požadavku nebo výsledná odpověď lze popsat jako jeden datový tok. Kombinovaná užitečná zátěž všech paketů datového toku představuje zprávy přenášené na aplikační vrstvě.
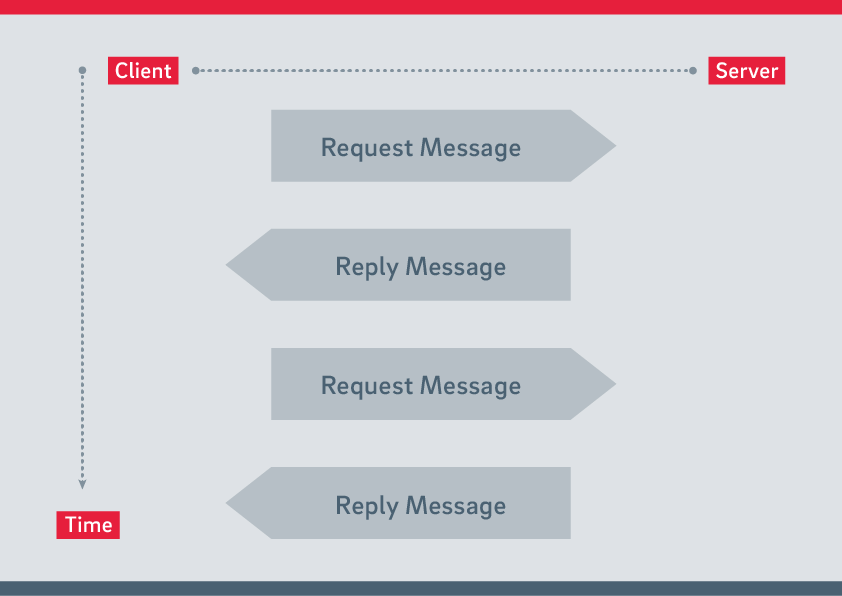
Obrázek 2 ukazuje jednoduchou operaci sestávající ze dvou sekvencí požadavků a odpovědí. Ilustruje základní toky paketů v síti, kde je každá zpráva rozdělena do tří datových paketů. Druhý diagram je aplikačně orientovaný pohled, který ukazuje výměnu informací.
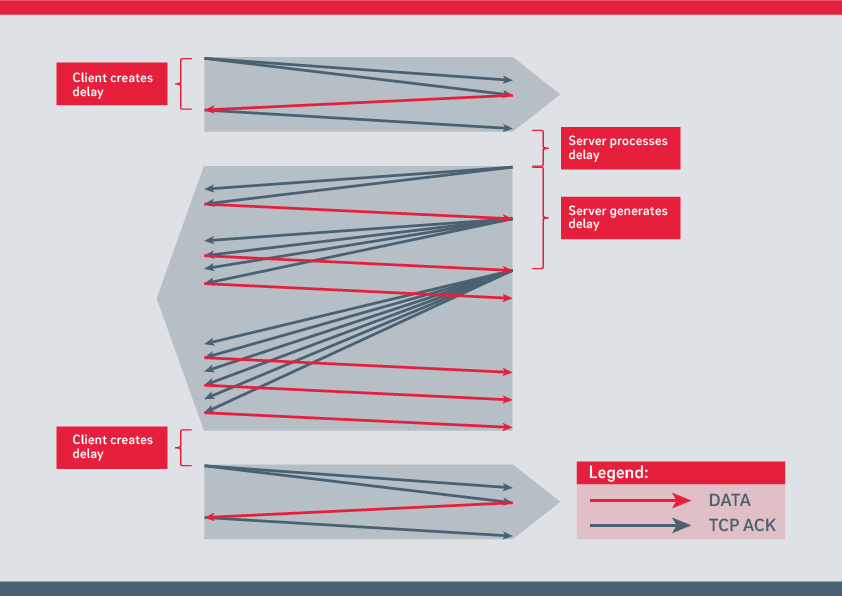
Pro analýzu výkonu aplikace a provozního výkonu zvlášť, je nutné prozkoumat faktory, které ovlivňují přenos provozního požadavku a výslednou odezvu. Rozdíl spočívá v době zpracování klientů a serverů a zpožděních na přenosovém médiu. Pokud je vývojový diagram rozšířen, celkové zpoždění je rozděleno do následujících čtyř kategorií:
Čas přenosu zprávy od klienta při odesílání,
Zpoždění vzniklá zpracováním na serveru,
Čas přenosu zprávy od serveru při odesílání odpovědi,
Zpoždění vziklá zpracováním na klientovi.
 Obrázek 4: Zprávy požadavků a odpovědí jsou přenášeny sítí ve formě paketů
Obrázek 4: Zprávy požadavků a odpovědí jsou přenášeny sítí ve formě paketů
Měření zpoždění zpracování serveru začíná v okamžiku, kdy server přijal poslední paket požadavku klienta. Tento paket také představuje konec zprávy požadavku. Zpoždění zpracování serveru končí prvním paketem odpovědi. Tento paket také představuje začátek zprávy s odpovědí.
Měření přenosového zpoždění začíná prvním paketem vyslaným serverem jako odpověď na dříve přijatý požadavek a končí posledním paketem sekvence odpovědí. Tato skupina paketů představuje celou zprávu přenášenou sítí.
Obrázek 5 ukazuje, jak Allegro Multimetr zobrazuje doby odezvy aplikační vrstvy pro provoz SSL. Na levé straně jsou zobrazeny časy pro vytvoření šifrování. Na pravé straně je zobrazena doba trvání odpovědi na zašifrovaný požadavek (čas mezi prvním klientským paketem a prvním paketem odpovědi serveru).
Popsaná měření vstupují do rámce analýzy výkonnosti. Tento rámec popisuje devět potenciálních překážek výkonu mezi klienty, sítí a servery. Proto by každé hodnocení výkonu aplikace mělo analyzovat všech devět problémových oblastí:
zpoždění vzniklá zpracováním na serveru,
zpoždění vzniklá zpracováním na klientovi,
Úzká hrdla sítě,
Ztráty paketů,
Řízení toku (zero window),
Upovídané protokoly kombinované s dlouhými prodlevami (protokoly co požadují, aby klient nebo server čekali na potvrzení)
Řízení toku na aplikační vrstvě (okna aplikace),
Algoritmus Nagle,
Algoritmus pomalého startu TCP.
PROFiber Networking CZ s.r.o.
Mezi Vodami 205/29
143 00 Praha 4
Tel.: + 420 225 152 050
info[zavinac]profiber.eu
www.profiber.eu
PROFiber Networking s.r.o.
Bernolákova 2
917 01 Trnava
Tel.: + 421 335 522 355
info[zavinac]profiber.eu
www.profiber.eu





 linked in
linked in